 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORTHOBO: Orthogonal Bayesian Hyperparameter Optimization
May 07, 2026Bayesian optimization is widely used for hyperparameter optimization when model evaluations are expensive; however, noisy acquisition estimates can lead to unstable decisions. We identify acquisition estimation noise as a failure mode that was previously overlooked: even when the surrogate model and acquisition target are correctly specified, finite-sample Monte Carlo error can perturb acquisition values. This can, in turn, flip candidate rankings and lead to suboptimal BO decisions. As a remedy, we aim at variance reduction and propose an orthogonal acquisition estimator that subtracts an optimally weighted score-function control variate, which yields an acquisition residual orthogonal to posterior score directions and which thus reduces Monte Carlo variance. We further introduce OrthoBO: a Bayesian optimization framework that combines our orthogonal acquisition estimator with ensemble surrogates and an outer log transformation. We show theoretically that our estimator preserves the target, leads to variance reduction, and improves pairwise ranking stability. We further verify the theoretical properties of OrthoBO through numerical experiments where our framework reduces acquisition estimation variance, stabilizes candidate rankings, and achieves strong performance. We also demonstrate the downstream utility of OrthoBO in hyperparameter optimization for neural network training and fine-tuning.
Robust Learning Under Label Noise With Iterative Noise-Filtering
Jun 01, 2019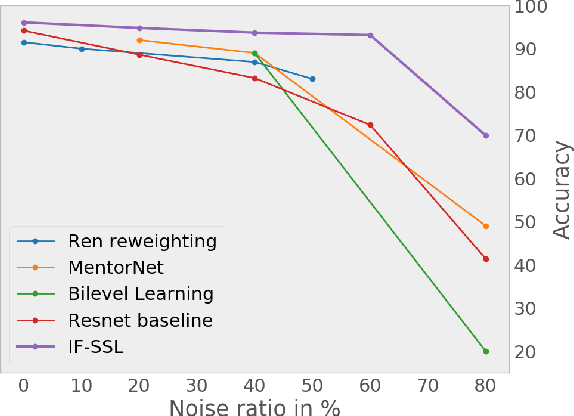
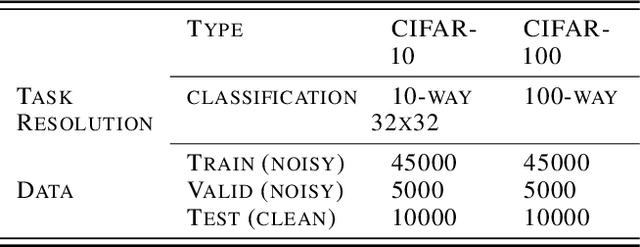
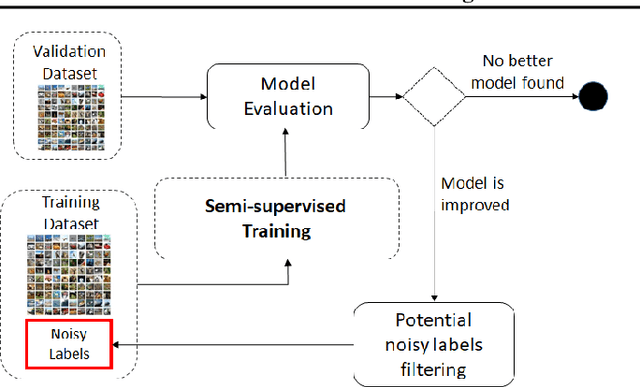
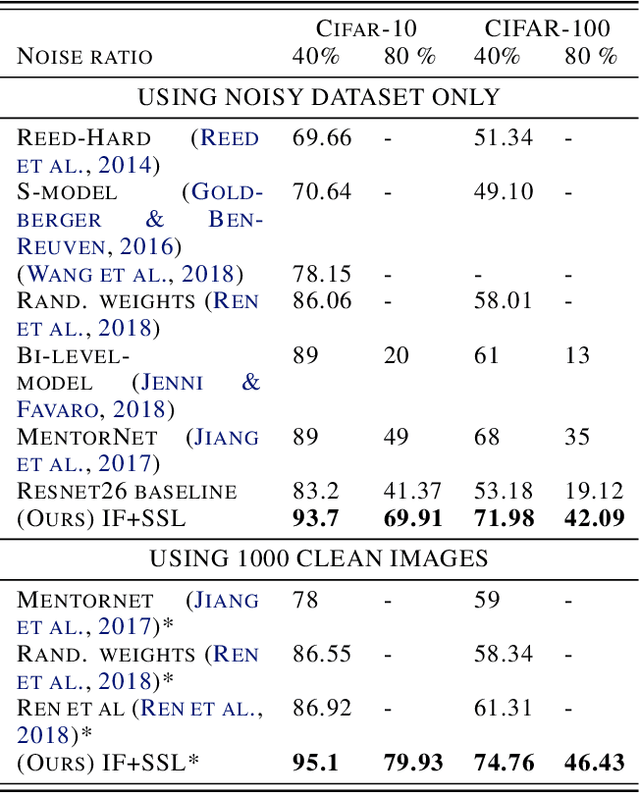
We consider the problem of training a model under the presence of label noise. Current approaches identify samples with potentially incorrect labels and reduce their influence on the learning process by either assigning lower weights to them or completely removing them from the training set. In the first case the model however still learns from noisy labels; in the latter approach, good training data can be lost. In this paper, we propose an iterative semi-supervised mechanism for robust learning which excludes noisy labels but is still able to learn from the corresponding samples. To this end, we add an unsupervised loss term that also serves as a regularizer against the remaining label noise. We evaluate our approach on common classification tasks with different noise ratios. Our robust models outperform the state-of-the-art methods by a large margin. Especially for very large noise ratios, we achieve up to 20 % absolute improvement compared to the previous best model.
Consistency-based anomaly detection with adaptive multiple-hypotheses predictions
Oct 31, 2018

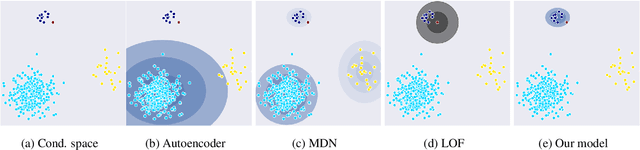
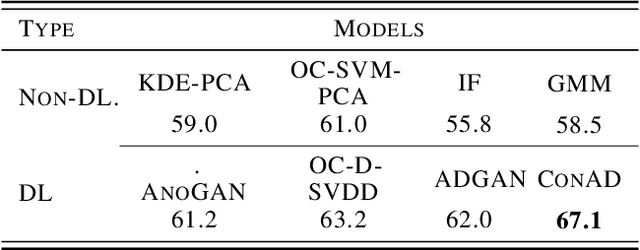
In out-of-distribution classification tasks, only some classes - the normal cases - can be modeled with data, whereas the variation of all possible anomalies is too large to be described sufficiently by samples. Thus, the wide-spread discriminative approaches cannot cover such learning tasks and rather generative models, which attempt to learn the input density of the ordinary cases, are used. However, generative models suffer under a large input dimensionality (as in images) and are typically inefficient learners. Motivated by the Local-Outlier-Factor (LOF) method, in this work, we propose to allow the network to directly estimate the local density functions since, for the detection of outliers, the local neighborhood is more important than the global one. At the same time, we retain consistency in the sense that the model must not support areas of the input space that are not covered by samples. Our method allows the model to identify out-of-distribution samples reliably. For the anomaly detection task on CIFAR-10, our ConAD model results in up to 5% points improvement over previously reported results.